The Science of 10 Key Ideas on Deepfake Detection

Haydar Talib
Dec 4, 2025

This article originally appeared on LinkedIn
Are you a speaker recognition or deepfake detection researcher? Are you someone who is, or wants to, build a deepfake detection product and want to get at the details right away?
Here it is, the paper on arXiv, have at it. If any of it is useful in your own work or publications, please cite our work and/or provide acknowledgment.
But for anyone who's sticking around, I offer here an abridged companion to the paper, highlighting its major revelations. This On Deepfake Voice Detection summary is intended to be more palatable to folks from outside the domain, or who may not have a lot of hands-on experience building such technologies, training AI models, etc.
It's all in the presentation
On Deepfake Voice Detection is really an expansion of one of the 10 Key Ideas on Deepfakes, namely -
Key Idea 5 – the datasets used to develop deepfake countermeasures must be realistic, rich and abundant
In my original post, we opened with a review of deepfake detection research, highlighting severe blindspots in the resulting models. The argument was that by relying entirely on a limited set of completely unrealistic data to train deepfake detection models, and to establish benchmarks for said models, the research community (and many industry practitioners) created a hermetic environment where they appeared to be developing accurate models, but that none of this supposed success would translate to real-world application.
Instead, we claim that when developing deepfake detection technology, you need to formulate a comprehensive view of the environment you plan on operating in, as illustrated below for the call center example.
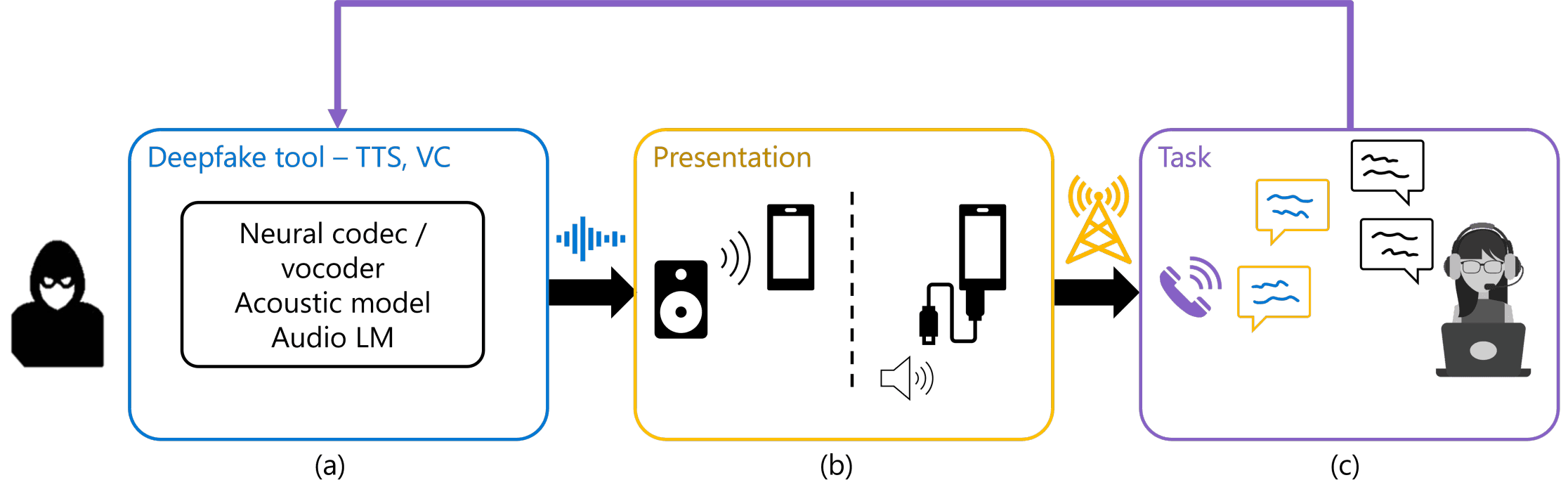
What a deepfake audio goes through in order to be applied to commit call center fraud
When a fraudster creates a deepfake voice or audio recording, that audio snippet doesn't teleport directly from the fraudster's computer and into your ear / deepfake detection model. Instead, the deepfake voice will go through a few steps before your deepfake detection tech gets it, and we call those steps the presentation (box (b) above) and task (box (c)) phases.
When the fraudster uses a tool to create a deepfake clone of your voice, they want to use this in a phone conversation with a call center agent (human or AI). So they would have to transmit the audio through the phone somehow; this is what we call the presentation phase, and it can be achieved in practice via loudspeaker playback, or by injecting the deepfake audio directly into the phone call, before it travels through the telephone network. The presentation phase has rarely been reflected in the datasets used to trained deepfake detection systems, if at all. Most systems stop at box (a) in the above diagram.
Finally, in the task phase, we have the actual interaction with the targeted organization. The fraudster uses the deepfake voice to carry out a conversation with the agent. All the datasets used in academic benchmarks, to our knowledge, are non-conversational audio. They're typically sourced from audiobook recordings and broken down into disjoint snippets of a couple seconds in duration.
It's all in the data
Our paper has a lot to say about data, because it really is all about the data. Most academic publications on deepfake detection in recent years put the bulk of their efforts into playing the hamster wheel game of trying new models, new neural network architectures, incrementally improving upon performance agains the established benchmarks. But the benchmarks are inherently limited, and we argue that researchers and practitioners worldwide need to spend more time and care into crafting their datasets. It's not fun work, it's hard work, but it's necessary if you want to build reliable systems; especially ones that you intend to sell to organizations or individuals worldwide.
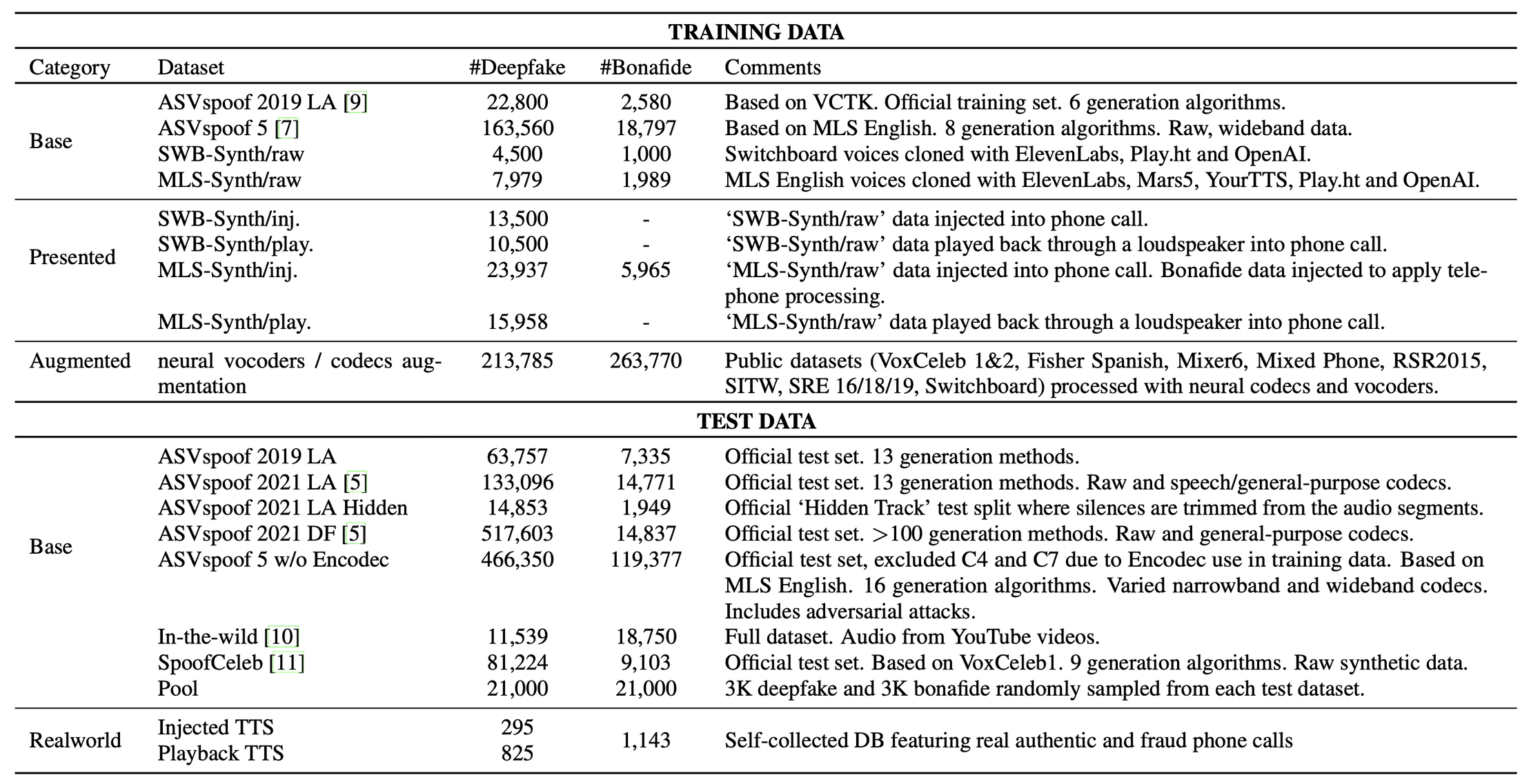
Your starter recipe for training and testing your deepfake detection technology
We're only going to squint at the above table to get the general idea of what we're looking at, but it displays a full recipe for setting up training data (used to build your deepfake detection model) and test data (used to measure the accuracy of your model).
The two major takeaways from the table are -
There is a separation between training and test datasets that goes beyond partitions. Some datasets are used exclusively to train the model, others exclusively to test the model
The most realistic dataset, Realworld, capturing our full presentation and task pipeline is only used to test the model
The first point may seem obvious, but it isn't necessarily so. Our paper describes, to our knowledge, the largest variety of datasets used in deepfake detection. Typically other work in the community may only focus on one or two datasets at a time. What this leads to in terms of separating training and test data is that both are taken from the same dataset, but split according to users and audio clips such that there's no overlap. For example, if we have 10 recordings for Person A, and we use that as part of our training data, then none of Person A's data is used to test the deepfake detection model. This way you hope to minimize bias.
But limiting your technology development and analysis to only one or a small handful of datasets is what led to the blindspots I mentioned earlier. Using entirely different datasets for training and testing, sourced from different places, should make the models we build more robust and better able to generalize.
The second point itself contains two important ideas: (1) that we have in hand a dataset sourced from the real world, and (2) that this dataset is so valuable we use it only to test the model, and nothing like it is used in the training data; this should make it the toughest challenge for the model to face. That way if our model performs well against the Realworld dataset we become more confident around its ability to generalize to realistic environments.
Hopefully all of the above seems intuitive to you, and maybe even obvious. But the claims we make about the need to understand and capture the real world environment of deepfakes, as well as the strategy for collecting and curating datasets, are all novel to this publication of ours.
But we still need to prove out our claims.
It's all in the realism
We tested several state of the art deepfake detection models, and the details on each can be found in the paper on arXiv, I won't cover them here. Rather we'll focus on the analysis of how our proposed methodology impacts the quality of the models, which is encapsulated in the results graph below.
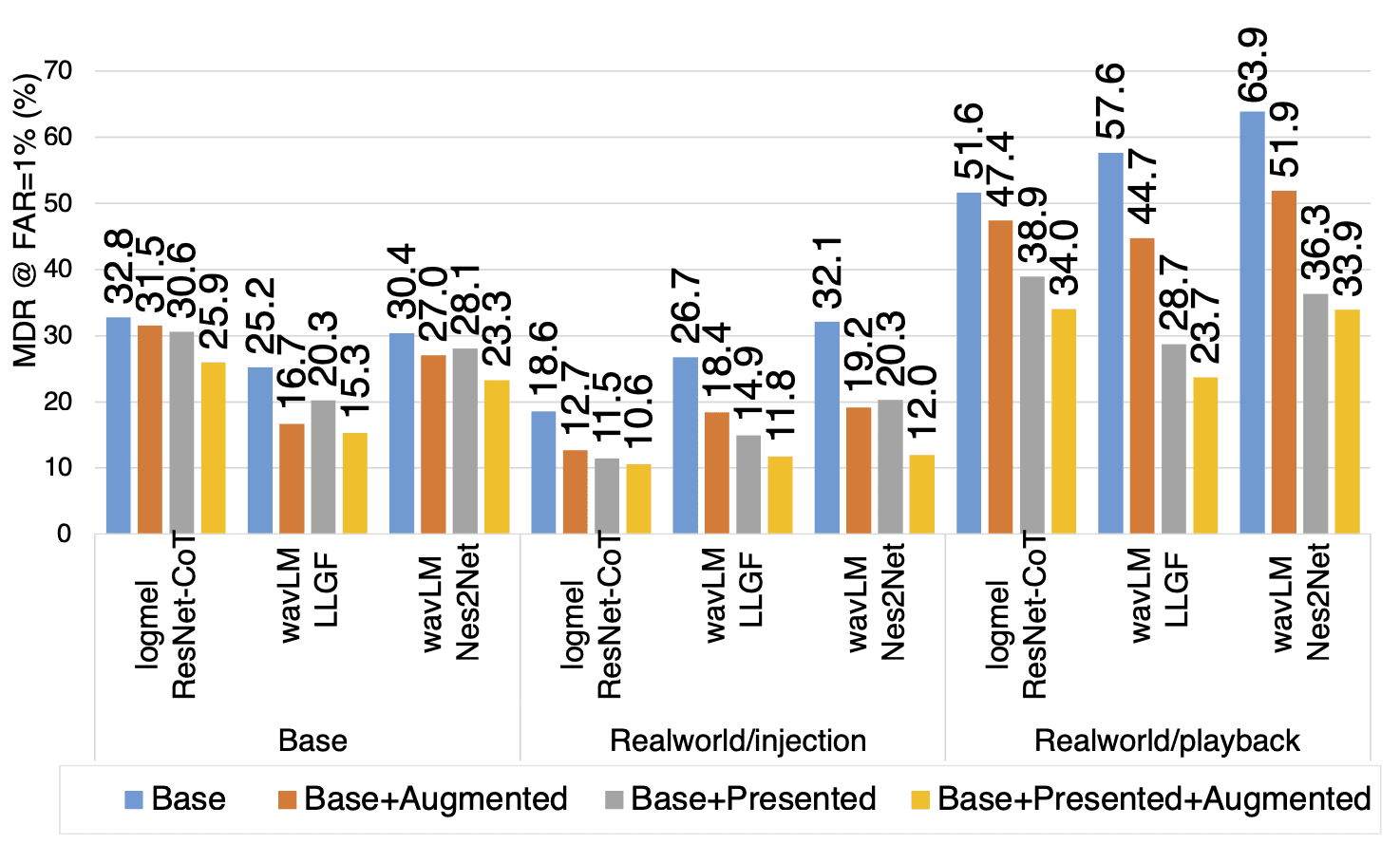
Results comparing several SOTA deepfake detection models using a variety of model training recipes against a variety of benchmarks
That is the version exactly as it appears in the paper, but we'll work with a simpler version that's easier to read.
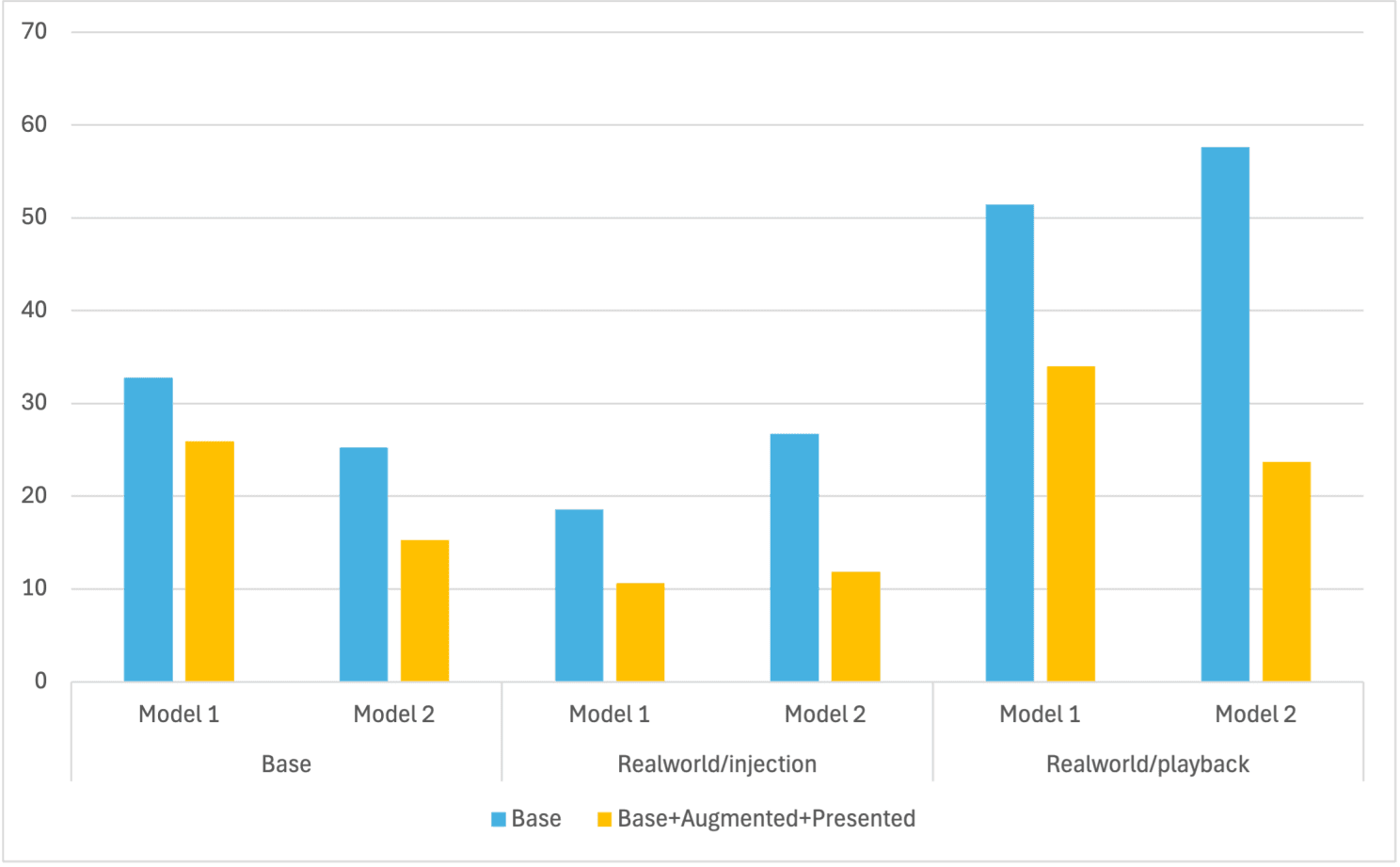
The simplified results chart, focusing on the first two deepfake detection models, and a subset of experiments
I removed the third model in the comparison, and simplified the names of the others to "Model 1" and "Model 2." I've also removed the gray and orange bars, which showed intermediate results.
But even this so-called simpler view can be tricky to parse. The blue bars represent our baseline performance, where the shorter bars mean lower error (which is what we want). The yellow-gold bars are the results after applying our recommended approach to building datasets.
The major takeaway here is that if you were to follow our recommended approach to building your datasets to train deepfake detection models, your models will become more accurate than when you use more traditional approaches. That is to say, our claim that you need to capture presentation (realism) in your training datasets is true. And this is regardless of your choice of model, as we see a similar pattern for Model 1 and Model 2.
To see what I'm talking about, what you're comparing is each of the yellow-gold bars to the corresponding blue ones. Without exception the yellow-gold bar is always lower than the neighboring blue one, which means lower error.
I will end with one last insight from the above results, one meant to convince us that our approach will help your deepfake detection model not only perform better in real world practice, but that it will also generalize better to new environments.
Let's say you build a new deepfake detection model using several publicly available datasets in the traditional way, without applying any of the additional steps we recommend in our paper. And when I tell you that on the real world dataset, my version performs better (which is what I just said above), you might argue -
"Sure, your model performs better in the real world because it has more data, but it also performs better on the test datasets I used for my model. So you haven't proven to me that realism in training data means especially better performance in the real world. All you've done is show me that it's better overall."
How can we answer that counterargument using our results?
Well, what will be interesting to see is the delta of errors across the different experiments.
What confounds us a bit in the above is that Model 1 and Model 2 show different patterns for when blue bars are higher or lower as we move from the Base test sets (farthest to the left) to the Realworld ones (middle and rightmost bars).
But if my claims are correct, then for each model, the degradation of accuracy as you move from the more ideal Base test to the Realworld tests should be worse for the blue bars than it is for the yellow-gold bars.
Why a degradation of accuracy? Because no matter how good your training data is, my expectation is it will usually perform worse in the Realworld environment than it would on cleaner academic datasets. But even as things get worse for all models when they're moved to reality, my claim is that they will get much worse for those models that were not trained using realistic data.
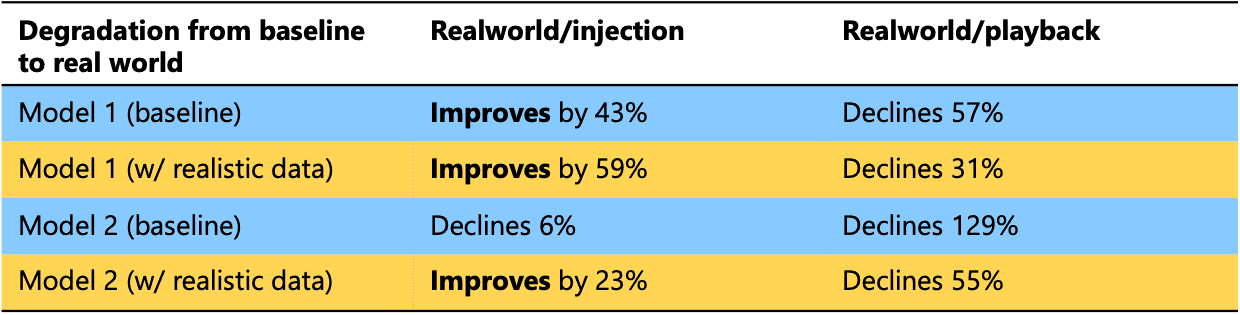
Comparing rate of decline for different models as they move from an ideal scenario to a real world one
What we're comparing is, for each model, how severely accuracy declines as we take the model from the idealized Base test setup to the Realworld ones. For each Model (1 or 2), we're comparing its blue row to the corresponding orange one (colors chosen to align with the ones from the bar chart).
What we then see is that, regardless of how a model's accuracy changes as it moves to the Realworld scenarios, the model trained with realistic data (orange rows) adapts better than the one trained using less realistic data (blue rows). If a blue (baseline) model declines by a certain amount, the orange (w/ realistic data) one declines less. Conversely, if a blue model improves, the orange one improves more. In other words, not only are the orange rows more accurate (lower error, as shown earlier in the bar chart), they are less adversely affected when they're challenged with new (real world) scenarios (the above table). They generalize better.
Carefully building your deepfake detection datasets, paying particular attention to capturing more realism, leads not only to overall higher accuracy but will also allow your models to perform more consistently in new, unseen scenarios.
This was the premise of Key Idea 5, now backed by experimental validation.
Once again, you can find our paper on arXiv.









