Data must be realistic, rich and abundant

Haydar Talib
Dec 5, 2024

This article originally appeared on LinkedIn
Key Idea 5 – the datasets used to develop deepfake countermeasures must be realistic, rich and abundant
In Key Ideas 3 and 4, we laid the building blocks for the technological foundation that scientists and technologists should use as they develop voice authentication and spoofing countermeasures technologies. Specifically, I advocated that both technologies must be developed concurrently to ensure that we remain safe and effective against the threat of deepfakes.
If you’re developing voice authentication technology today, you also need to develop spoofing countermeasures if not already done so, and vice versa.
One of the big reasons for that guidance is that spoof datasets would become part of the voice authentication development and testing process, designing robustness into the technologists’ practice.
But what is spoof data exactly? Where do we get the large amounts of deepfake audio needed to train AI models?
Until very recently, the majority of data used to develop and train antispoofing technologies has come from staged studio recordings, only available in small quantities.
More recently, audiobooks have been added to the mix. Audiobooks have been a real boon to antispoofing research since they provide tens of thousands of hours of clean recordings of human speech, often by professional actors recorded using professional equipment.
Furthermore, with the growing availability of dozens of open-source or readily-available custom TTS (text-to-speech) technologies, researchers could easily generate tens of thousands of hours worth of voice clone samples.
The same audiobook recordings have been used to develop the custom TTS tech in the first place; you’ve already heard a few samples way back in Key Idea 1.
In the world of AI research, data is king. Unsurprisingly, with this abundance of data and advances in Deep Neural Networks, synthetic speech detection (SSD) got much better at spotting deepfakes. Compiling the performance of state-of-the-art systems over the past few ASVspoof challenge datasets, the results are extremely impressive.
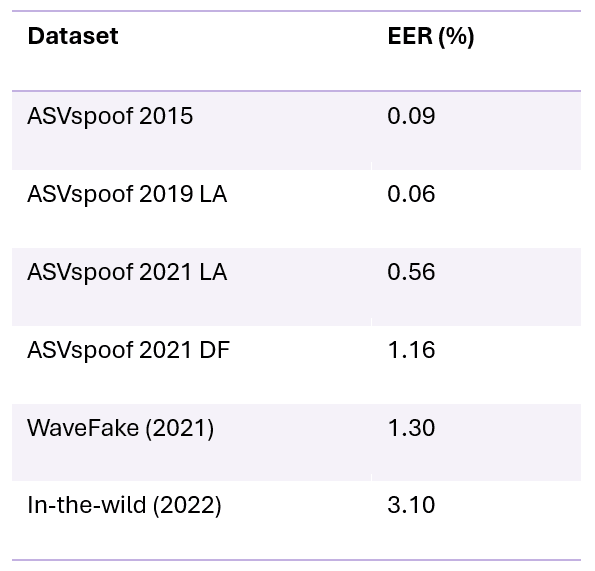
Error rates of spoofing countermeasures against a variety of deepfake datasets used by industry and the scientific community to develop deepfake detection technology
Even though we see a slight upward trend in terms of error, the overall accuracy of state-of-the-art systems is extremely high. With such countermeasures in place, we are thankfully safe from deepfakes, right?
There is just one problem: these results, while technically true, were masking extremely fragile systems.
At around the time of ASVspoof 2019, some work was being done to study more carefully what the neural networks built to detect deepfakes were actually detecting (early discovery by Chettri and Sturm, and further developed in this paper).
What these works posited was that due to the manner in which the synthetic voice datasets were created, the audio snippets contained no silences; meaning that the synthetic voice would speak continuously for the duration of the several seconds of audio. Recordings of the real people (actors), as expected, had silences at the beginning or end of the recordings, as well as small pauses between words or syllables.
So an AI model would only have to learn that if there was silence present in a recording, then it was more likely to be human and, conversely, if there was no silence present it was more likely to be a synthetic voice. While I’m exaggerating the effect here (the models still learned useful characteristics as well), the achievable accuracy using this simple silence-based approach was around 85%!
For the 2021 ASVspoof challenge, the evaluation team began to slightly modify the presence/absence of short silences in the audio clips, revealing the following results.
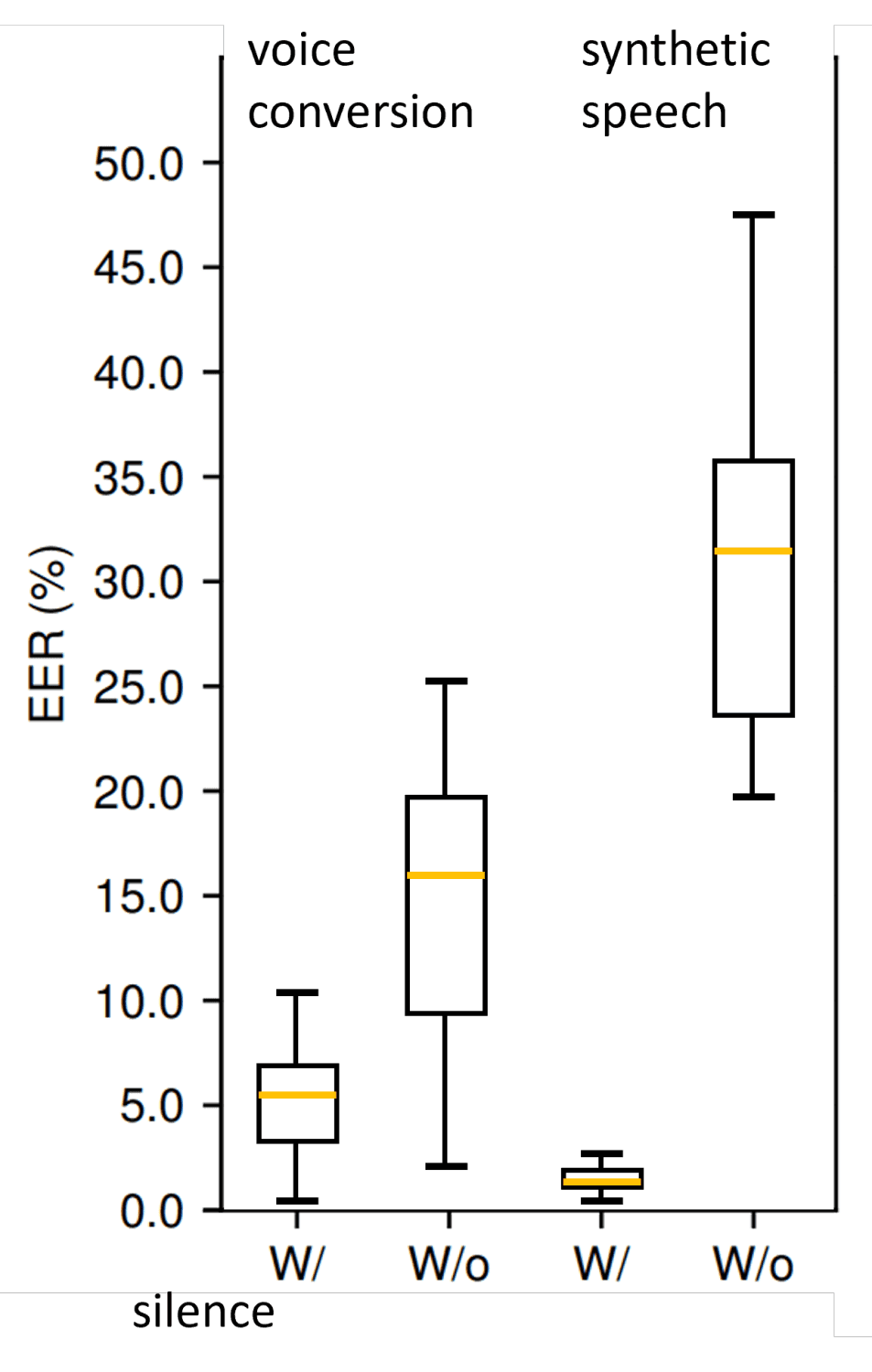
Box plot of spoofing countermeasure error (EER) comparing performance when silence is present in audio and when silence is removed. Two types of deepfake compared: voice conversion (left) and synthetic speech (right) Source: ASVspoof 2021
The error rates for the highest-performing systems went up dramatically, and most systems participating in the 2021 ASVspoof workshop saw a decline in performance; the evaluation now comprised a manipulated-silence scenario, against which modern spoofing countermeasure technologies were still fragile. This confirmed the earlier works that revealed how state-of-the-art deepfake detection systems were confounding deepfake audio features with secondary characteristics of the specific datasets on which they were developed/trained.
The scientific community was so caught up in improving on its own benchmarks, boasting accuracies on the order of 99%, that it didn’t realize that the datasets had one dangerous flaw: the unintentional silence pattern. If you tugged at that innocuous little brick, suddenly the entire reality would collapse.
By the 2024 edition of ASVspoof, a small minority of spoofing countermeasures systems were updated to address this blind spot, and we finally started to get a sense of a more realistic performance of these systems. If we revisit our initial table of results from above, it now looks like –
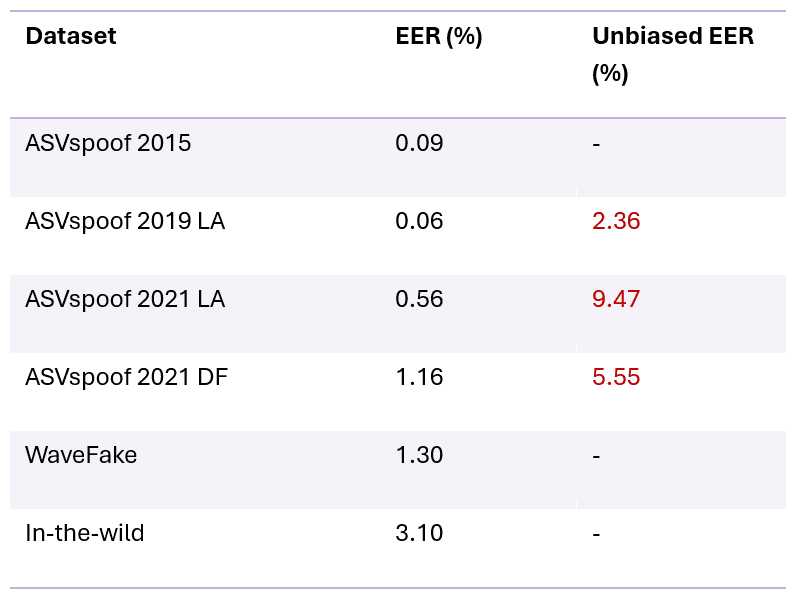
For ASVspoof 2024, state of the art spoofing countermeasure systems were starting to be updated to avoid the pitfall of the silence-related flaw. New error rates are available for some of the benchmark datasets, as shown in the rightmost column
The rightmost column now shows the error rates of the updated state of the art in spoofing countermeasures. Error rates are still much higher than the earlier benchmarks, perhaps indicating a more realistic view of real-world performance.
Moving along, and taking this discovery on the nature of datasets further: what else might be wrong with them? If AI technologies are entirely shaped by the nature of the data used to train the underlying models, how do we ensure that we’re building the right defenses against real-world use of Deepfakes?
The answer, and message of today’s Key Idea, are quite simple –
The datasets used to develop and evaluate spoofing countermeasures (as well as voice authentication technology) must reflect the real world in which these technologies are intended to operate
If we use the example of voice authentication in the world of telephony, it means that the audio clips must be recordings of telephone conversations; where real people are talking in their natural manner about a variety of realistic subjects.
Phone conversations don’t sound like actors reading books in a professional recording studio.
Along similar lines, we’ve got to capture the use of deepfake voices in a realistic manner. Which is why our audiobook recordings fail again, but so do all the journalist demonstrations of voice clone technology.
Many of these demonstrations are unrealistic since the “fraudster” and “victim” are the same person, with unique access to their own voice and a variety of other advantages akin to knowing the combination to the padlock they’re “breaking into.”
In the best case scenario, due to the lack of realism, such demonstrations don’t teach us much insofar as what criminals are likely to do.
But really, if we took a step backward, the voice deepfake demonstrations performed by journalists is tantamount to attempted fraud or security breach (oh BBC, what has happened to your storied institution?), a subject we will likely revisit in a future article.
Before we get curious/excited to see for ourselves, a friendly word of caution: do not try any of this at home. Something the journalists should have been warning their readership about.
Folks – do not play games with your bank’s, or any other institution’s, security measures.
You could set off all sorts of alarms in your bank’s security systems (which would be the correct outcome), causing you headaches you probably don’t need.
Ahem, let’s get back to talking data.
The 2024 edition of ASVspoof has already taken positive first steps towards including more advanced deepfake methods, and more realistic spoof data conditions, including the use of non-studio-quality audio. Though the datasets are still comprised of audiobook recordings. Perhaps the most realistic dataset would be the In-the-Wild dataset; this one is sourced from social media (YouTube and others), is reasonably large, but does not reflect call center conversations.
While the spoofing countermeasures scientific community has slowly begun adjusting to the real world when it comes to deepfakes, there is still much work ahead in terms of improving datasets so we can truly call the so-called state-of-the-art technologies, “state of the art.”
The following points make up a primer of what to aim for when building/collecting deepfake datasets –
Realism – what would a fraudster do? For your use case or domain, you likely need to recreate all the steps a real world fraudster/criminal would have to go through, including any limitations/advantages they have, to generate valuable data to use for training/testing your spoofing countermeasures.
Richness – data from all the deepfake technologies that might be used, types of loudspeakers, population demographics, spoken language, accent, etc.
Abundance – self-explanatory. You generally need large volumes of data to develop and evaluate powerful AI models for spoofing countermeasures
Keeping the above in mind will help ensure that we are collectively addressing the real problem and building technologies and processes that will keep us safe.
Otherwise, whether it’s the scientific community as a whole, or individual (perhaps well-meaning) journalists, when you’re working with inadequate data or unrealistic conditions, you’re likely going down the wrong rabbit hole. And the discoveries you think you’ve made may have some element of truth to them, but may in fact be leading you down a catastrophic path.
tldr; you need realistic data, and to keep updating it as new deepfake technologies emerge. The data (and other assumptions) used for deepfake detection research should align with real-world use cases. Doing otherwise may not only skew your results, but completely invalidate your claims of developing state-of-the-art technology.









